
Top 6 AI Vector Databases Compared (2025): Which One Should You Choose as an AI Builder?
A Deep Dive into the Best Vector Databases for AI Developers in 2025 🚀


Vector databases have become an indispensable tool in modern AI workflows, particularly in retrieval-augmented generation (RAG), semantic search, recommendation systems, and multimodal applications.
While they have been a crucial part of machine learning systems for years—powering personalized recommendations and similarity search—their adoption surged after the rise of large language models (LLMs) like ChatGPT.

Before ChatGPT, most teams relied on predefined keyword-based search systems to retrieve information.
However, as LLMs gained prominence, organizations faced challenges in storing, retrieving, and efficiently searching through vast high-dimensional vector embeddings.
Vector databases address this issue by allowing quick and scalable similarity searches, which makes them a fundamental part of modern AI infrastructure.
📈 Why Has Interest in Vector Databases Grown?
In 2023, the explosion of AI applications drove massive investments in vector databases. Some key factors include:
📌 The Rise of Retrieval-Augmented Generation (RAG): AI developers recognized that LLMs have limitations in factual consistency. By integrating vector databases, AI systems and agentic applications could retrieve external knowledge and improve response accuracy.
📌 Increased AI Infrastructure Investment: Startups like Pinecone and Weviate have raised millions in funding to develop specialized vector database solutions optimized for different use cases.
📌 Scaling AI Search Beyond Text: Traditional search engines struggle with high-dimensional data like images, audio, and video embeddings. Vector databases power multimodal search, enabling AI to process and retrieve diverse data formats efficiently.
🎯 What to Expect in This Article
As we enter 2025, vector database technology continues to evolve. In this article, we will explore:
✅ Key applications and why vector databases matter for AI in 2025.
✅ Comparison of leading vector databases: strengths, weaknesses, and performance benchmarks.
✅ Industry trends shaping the future of vector search and AI infrastructure.
✅ Challenges in deploying vector databases for LLM applications in 2025.
This guide provides an in-depth look at the top solutions in the space and what you need to consider when choosing the right vector database for your AI applications.
Let’s dive in. 🚀
The Landscape of Vector Databases in 2025
We have seen the need for efficient vector search and retrieval grow as AI models that researchers and engineers at larger firms build and deploy increasingly rely on high-dimensional vector representations.
The vector search ecosystem consists of:
Vector Search Algorithms – The core techniques used for fast and accurate similarity search.
Vector Databases – Full-fledged database systems that store and index vector embeddings for efficient retrieval.
Key Players in Vector Search
Several companies and research institutions have contributed to advancing vector search algorithms:
📌 Spotify → Developed ANNOY, a memory-efficient Approximate Nearest Neighbors (ANN) algorithm optimized for large-scale recommendation systems.
📌 Meta (Facebook AI) → Developed FAISS, one of the most widely used libraries for high-speed similarity search.
📌 Google → Developed ScaNN, a highly efficient ANN search technique optimized for high-speed, large-scale AI inference.
📌 Microsoft → Contributed to PQ (Product Quantization), which improves search efficiency through efficient vector indexing by compressing high-dimensional vectors.
These algorithms power many modern AI applications, including semantic search, recommendation systems, and AI-powered retrieval models.

How We Categorize Vector Databases: Dedicated vs Vector-Enabled
With many devs shipping many visual search engines, agentic AI with UX and personalization as MOAT, and LLM-powered applications, companies now require specialized storage solutions for high-dimensional data.
💨 DETOUR: AI Agent UX Patterns: Lessons From 1000 Startups - Jonas Braadbaart
All of those have led to two major categories of vector databases:
1️⃣ Dedicated Vector Databases
These are purpose-built for storing, indexing, and retrieving vector embeddings efficiently. They integrate optimized search algorithms (e.g., FAISS, HNSW, PQ) and provide faster similarity searches compared to general-purpose databases.
Examples:
Milvus (Zilliz) – An open-source, high-performance vector database.
ChromaDB – Popular for embedding-based LLM applications and AI-native workflows.
Qdrant – Rust-based, optimized for performance.
Pinecone – Optimized for serverless, real-time vector search.
Weaviate – Open-source and supports hybrid search (vector + keyword-based).
LanceDB – Columnar vector database optimized for real-time AI use cases and analytics workloads.
2️⃣ Vector-Enabled General Databases
Traditional databases have added support for vector similarity search to handle AI workloads.
While not as optimized as dedicated vector DBs, they are suitable for hybrid applications requiring structured and unstructured data retrieval.
Examples:
Redis: In-memory database that supports vector similarity search with the Redis Search module.
Elasticsearch: Popular for hybrid search combining full-text search with vector retrieval.
PostgreSQL (PGVector): SQL (relational) database with vector indexing support via search extensions.
MongoDB Atlas: MongoDB provides a fully managed vector database within its Atlas cloud service, supporting vector embeddings alongside live application data.
📌 Key Insight: Dedicated vector databases outperform general-purpose databases in handling large-scale vector similarity searches, making them the preferred choice for devs building and shipping AI applications.

The Rise of RAG & AI-Powered Search
With the commercialization of LLMs and retrieval-augmented generation (RAG), organizations have increasingly turned to vector databases to enhance AI-driven applications.
This article will focus on dedicated vector databases to help you choose the best option for your 2025 AI strategy.
Need creative, high-quality technical content? Happy to chat! Book a call with our Creative Engineers👇🏾
Comparing Dedicated Vector Databases (DBs)
Choosing the right vector database depends on your specific use case, indexing requirements, hosting flexibility, and cost.
This section compares the most widely used dedicated vector databases based on the following criteria:
📌 Indexing Methods and Search Algorithms: Determines query speed and efficiency. What similarity search techniques are supported? (e.g., FAISS, HNSW, PQ).
📌 Scalability and Performance: How well the database handles large datasets and concurrent queries. Does it support horizontal scaling (distributed nodes) or vertical scaling (single-node optimization)?
📌 Data Persistence and Reliability: Ensures fault tolerance, high availability, and replication strategies.
📌 Integration Ecosystem: Compatibility with frameworks like LangChain, OpenAI, LlamaIndex, Hugging Face, and other AI toolchains.
📌 Security and Compliance: Encryption, authentication, role-based access control (RBAC), and regulatory compliance (GDPR, CCPA).
📌 Community and Support: Availability of documentation, forums, active user base, and enterprise support.
📌 Distribution and Licensing: Open-source vs. commercial offerings, free tiers, and enterprise support.
📌 Multi-modal Data Support: Can it store and retrieve text, images, video, and audio embeddings?
📌 Hosting Options: Cloud vs. self-hosted vs. hybrid deployments.
A Quick Landscape Overview of Dedicated Vector Databases (2025)

1️⃣ Milvus
Overview
Milvus is one of the leading open-source vector databases that supports multiple indexing algorithms and is designed for handling massive AI workloads.
Milvus has both self-hosted and fully managed versions (Zilliz Cloud). It is optimized for large-scale retrieval, high-speed indexing, and low-latency queries, making it ideal for AI-powered analytics and recommendation systems.

Key Features Based on Comparison Factors
✅ Indexing Methods and Search Algorithms: Supports HNSW, Inverted File with Product Quantization (IVF_PQ), FLAT, Inverted File Flat (IVF_FLAT), and ANNOY for flexible search optimization.
✅ Scalability and Performance: Designed for horizontal scaling, built for massive-scale data retrieval, and supports distributed deployments.
✅ Data Persistence and Reliability: Offers built-in fault tolerance, supports replication and high availability.
✅ Integration Ecosystem: Python (PyMilvus), Java, Go, and Node.js SDKs. Integrates with LangChain and OpenAI models.
✅ Security and Compliance: Provides role-based access control (RBAC), TLS encryption, and compliance with GDPR/CCPA.
✅ Community and Support: Large open-source community, active GitHub repo, Discord, Reddit, YouTube tutorials, and enterprise support available.
✅ Distribution and Licensing: Open-source (Apache 2.0) license with dedicated forums and enterprise support via Zilliz CLoud.
✅ Multi-modal Data Support: Primarily optimized for text and image embeddings but can be extended.
Hosting & Cost
📌 Self-hosted: Free under the open-source Apache 2.0 license.
📌 Managed (Zilliz Cloud):
Free plan includes 5 GB storage and 2.5M virtual compute units per month.
Pay-per-usage serverless plan from $0.3/GB per month.
Dedicated clusters from $99 per month.
Best For
Teams seeking a balance between open-source flexibility and managed services.
Organizations requiring scalability and multiple indexing options.
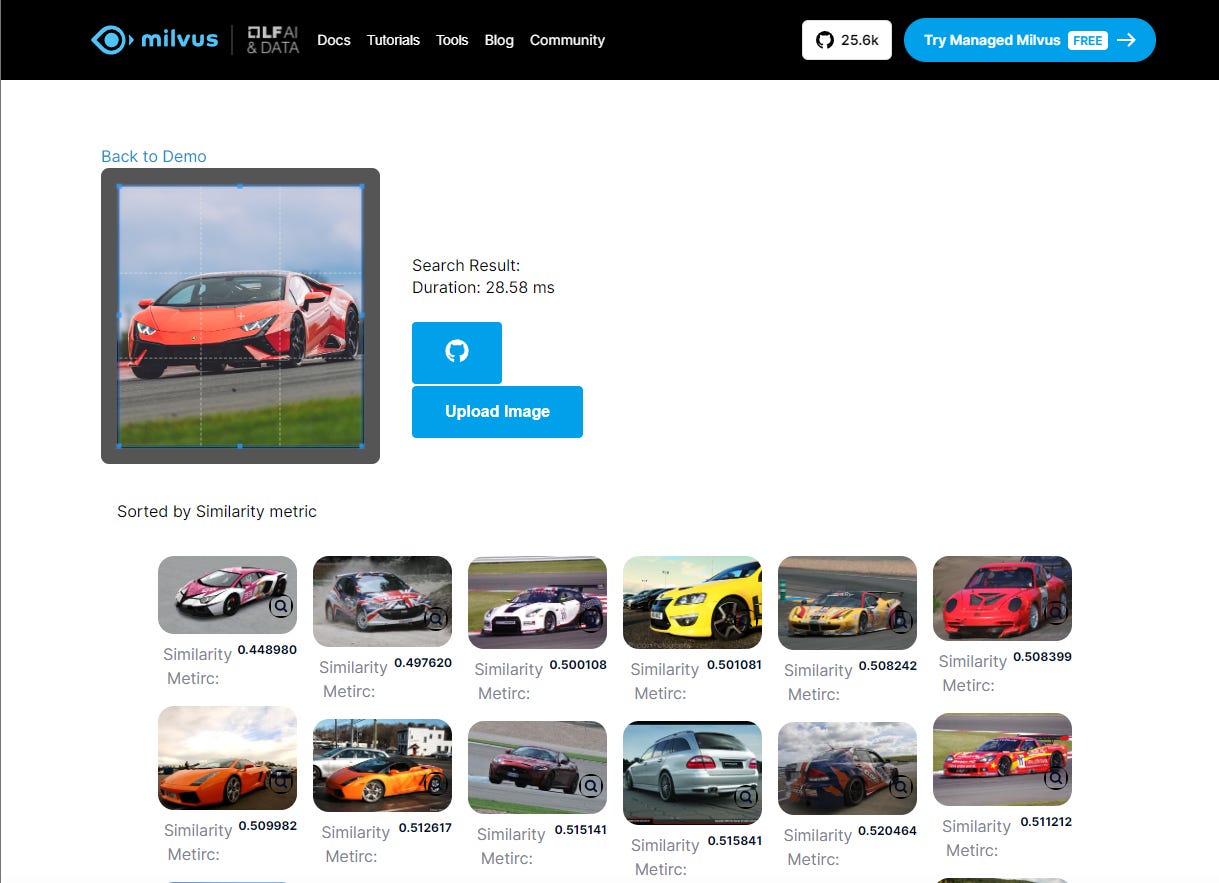
🚀 Get Started Here: Quickstart with Milvus Lite.
2️⃣ ChromaDB
Overview
ChromaDB is an open-source vector database tailored for local experimentation and an excellent choice for LLM and RAG-based applications.
It is lightweight, self-hosted, and well-integrated into the LangChain ecosystem.

Key Features Based on Comparison Factors
✅ Indexing Methods and Search Algorithms: Supports HNSW (Hierarchical Navigable Small World) as its default vector indexing algorithm for efficient similarity searches.
✅ Scalability and Performance: Suitable for local experimentation and small to medium-scale workloads but is evolving to support larger-scale deployments from Chroma 0.4.
✅ Data Persistence & Reliability: Operates as a single-node system, storing data locally. Efforts are underway to introduce features like checkpointing, snapshotting, and improved recovery systems.
✅ Integration Ecosystem: Tight integration with LangChain, LlamaIndex, and other frameworks for LLM-based applications. Use embedding models from OpenAI, HuggingFace, and Cohere. Deployment guides are available for cloud platforms including AWS, GCP, and Azure.
✅ Security and Compliance: Limited security options (as a self-hosted local DB) with basic authentication; lacks enterprise security features (like role-based access control, etc.)
✅ Community and Support: Fast-growing Discord community, extensive documentation.
✅ Distribution and Licensing: Open-source (Apache 2.0).
✅ Multi-modal Data Support: Supports text and multimodal embeddings.
Hosting & Cost
📌 Self-hosted: Free under the open-source Apache 2.0 license.
📌 Managed: Cloud waitlist available but not active yet. Third-party providers like Elestio offer fully managed hosting options for ChromaDB.
Best For
Developers prototyping RAG applications.
Teams working with LangChain and AI embeddings locally.

🚀 Get Started Here: Quickstart with Chroma.
3️⃣ Weaviate
Overview
Weaviate is a highly extensible,open-source vector database that supports GraphQL queries and offers hybrid search capabilities.
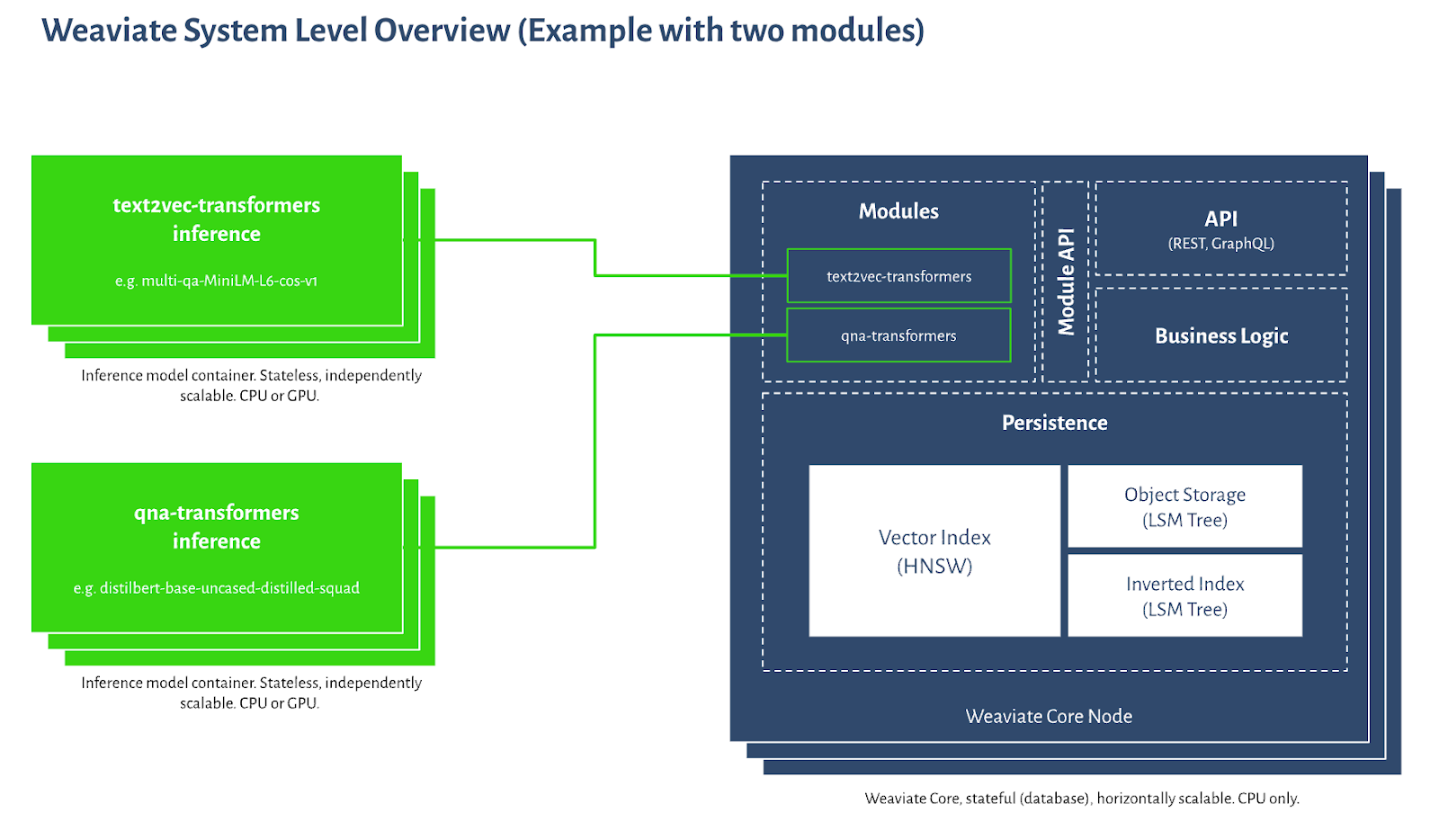
Key Features Based on the Comparison Factors
✅ Indexing Methods and Search Algorithms: Supports the following vector index types: flat indexing, HNSW, and dynamic indexing.
✅ Scalability and Performance: Supports horizontal scaling and hybrid search.
✅ Data Persistence and Reliability: Built-in replication, fault tolerance, and multi-node clustering.
✅ Integration Ecosystem: Integrates with various embedding model providers, including Hugging Face and OpenAI. It offers GraphQL and gRPC APIs for queries. Connects with LangChain, LlamaIndex, DSPy, and others.
✅ Security and Compliance: Enterprise-grade encryption and role-based access control (RBAC).
✅ Community and Support: Active developer community, accessible through its forum, and offers comprehensive documentation.
✅ Distribution and Licensing: Open-source (BSD-3-Clause license), managed cloud available.
✅ Multi-modal Data Support: Yes (text, image, audio, structured data embeddings).
Hosting & Cost
📌 Self-hosted (Open-source): Free
📌 Cloud version: Starts at $25/month (pay-as-you-go model).
Best For
Teams needing GraphQL-powered search capabilities.
AI applications requiring structured and unstructured data retrieval.
Organizations building custom hybrid search solutions.

🚀 Get Started Here: Quickstart with Weviate.
4️⃣ Pinecone
Overview
Pinecone is a fully managed, closed-source vector database known for high availability, serverless scaling, and optimized retrieval speeds with three distance metric types.
Pinecone offers serverless and pod-based indexes to users for storing records.
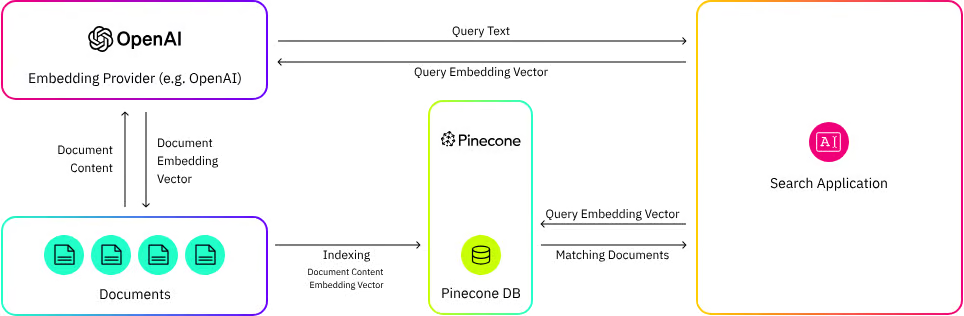
Key Features Based on Comparison Factors
✅ Indexing Methods and Search Algorithms: Utilizes proprietary indexing methods optimized for performance and scalability (likely SINNAMON).
✅ Scalability and Performance: Horizontally scalable, low-latency cloud-native solution optimized for high-performance distributed indexing.
✅ Data Persistence and Reliability: Auto-scaling, fully managed backups.
✅ Integration Ecosystem: Offers SDKs in various programming languages, such as Python, Node.js, Java, Go, .NET, and Rust, to interact with its vector database services.
✅ Security and Compliance: Enterprise-grade security, SOC2, GDPR/HIPPA compliance.
✅ Community and Support: Community forum, example notebooks and sample apps, commercial support with $100 serverless credits for new users.
✅ Distribution and Licensing: Closed-source, pay-per-use (commercial) pricing.
✅ Multi-modal Data Support: Can store and search vectors derived from various data modalities, including images and audio, depending on the embeddings the user generates.
Hosting & Cost
📌 Managed Cloud: Standard tier starts at $25 per month, which includes $15 per month of usage credits.
📌 Free Tier: $100 free credits for new users
Best For
Enterprises looking for a production-ready, fully managed vector database for RAG and LLM applications.
Accessible to smaller teams and individual developers due to its scalable, usage-based pricing model.
Developers looking for a plug-and-play vector search solution.
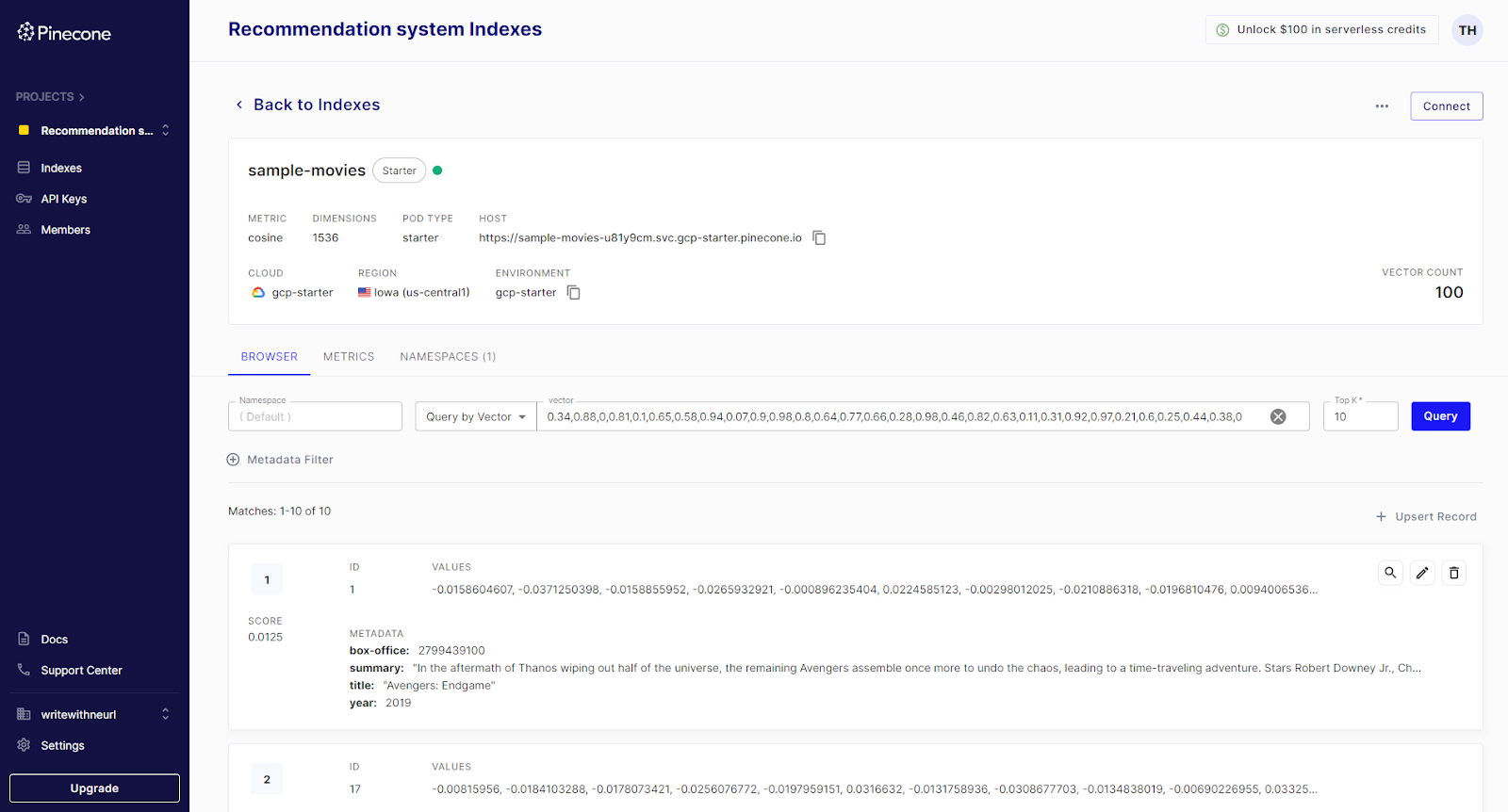
🚀 Get Started Here: Quickstart with Pinecone.
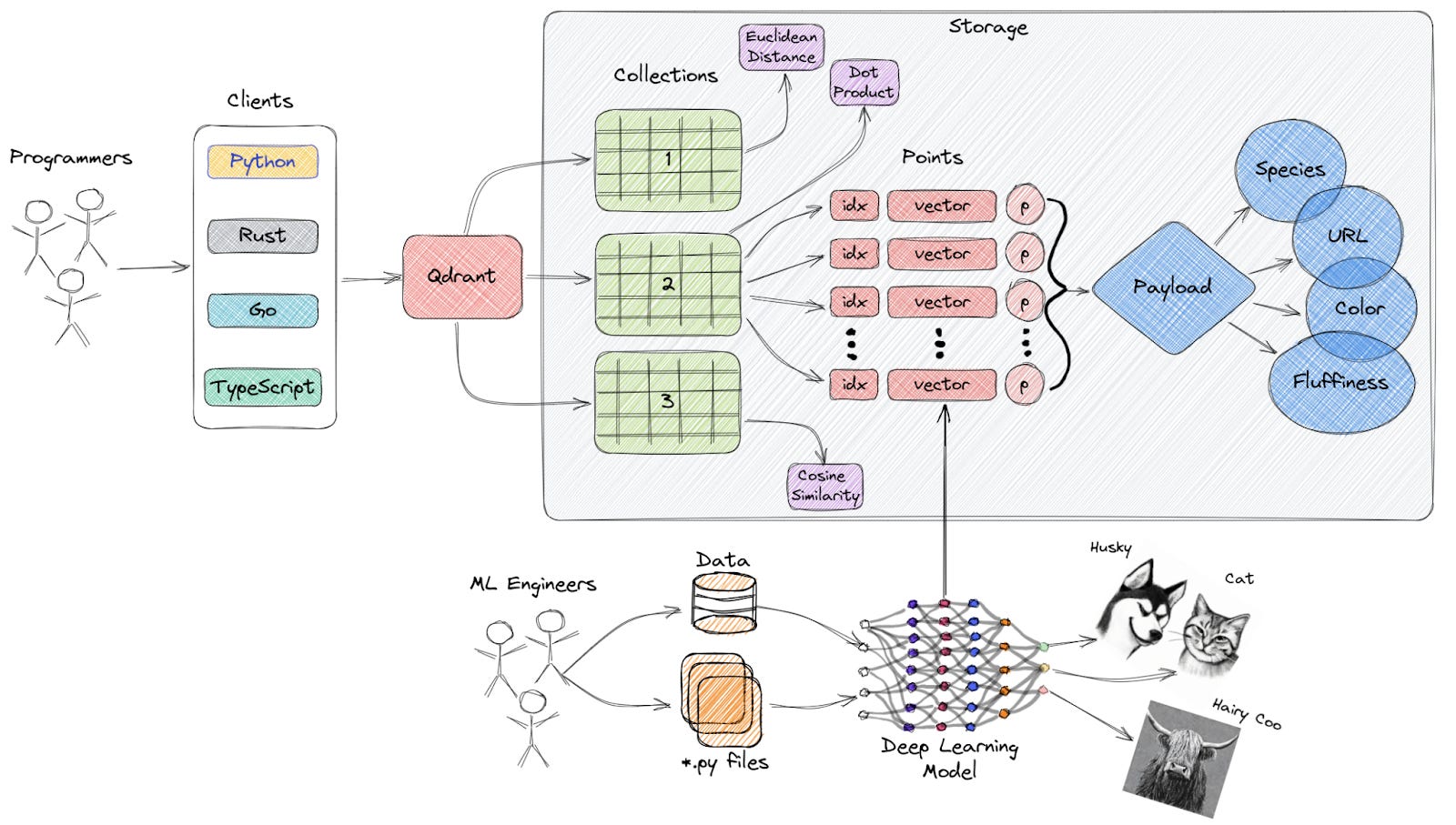
5️⃣ Qdrant
Overview
Qdrant is an open-source, Rust-based vector database designed for high-performance retrieval with low latency.
It is highly flexible, offering both self-hosted and fully managed cloud options, which makes it suitable for teams prioritizing precision and speed.
Key Features Based on Comparison Factors
✅ Indexing Methods and Search Algorithms: Supports HNSW, optimized for high recall and low latency. Also offers support for other indexing methods, such as scalar quantization and product quantization, which can be beneficial for reducing memory usage and improving search efficiency.
✅ Scalability and Performance: Benchmarked as highly precise with distributed scaling support for production use cases. However, achieving optimal performance in distributed setups requires careful configuration and consideration of factors such as network latency and data partitioning
✅ Data Persistence and Reliability: Ensures data persistence by writing all operations to disk, allowing recovery in case of failures. Additionally, Qdrant supports snapshots for backup and recovery purposes.
✅ Integration Ecosystem: Compatible with LangChain, LlamaIndex, DSPy, and others. Client libraries include Python, Rust, JavaScript, Go, .NET, and Java libraries. Qdrant offers both gRPC and REST APIs; the gRPC API is recommended for high-performance applications due to its lower latency.
✅ Security and Compliance: RBAC available for enterprise users (availability may depend on the specific deployment and licensing) with TLS encryption, authentication, and SOC 2 compliance.
✅ Community and Support: Active Discord community, detailed documentation with interactive examples, and robust support.
✅ Distribution and Licensing: Open-source (Apache 2.0), managed cloud available.
✅ Multi-modal Data Support: Designed to handle various types of vector embeddings, including those derived from images, audio, and other data modalities.
Hosting & Cost
📌 Self-hosted: Free open-source version.
📌 Managed Cloud: Starts at $0 for a 1GB cluster, with $0.014/hour for hybrid cloud instances. Refer to Qdrant's official pricing page for the most up-to-date information.
Best For
Teams that need low-latency, high-precision vector search for applications like semantic search and personalized recommendations.
AI teams that require self-hosted vector search with high recall.
Teams that are looking for an open-source alternative to Pinecone.
🚀 Get Started Here: Quickstart with Qdrant.
6️⃣ LanceDB
Overview
LanceDB is a self-hosted, open-source vector database tailored for multi-modal AI workflows.
Unlike traditional vector databases, LanceDB does not require managing database servers, which makes it great for small teams and developers experimenting with diverse data types.
Additionally, LanceDB Cloud is available as a hosted serverless solution for vector search, handling tasks like reindexing, compaction, and cleanup for larger-scale enterprise use cases.

Key Features Based on Comparison Factors
✅ Indexing Methods and Search Algorithms: Implements IVF_PQ and HNSW, optimized for partitioning and compression of large datasets.
✅ Scalability and Performance: Lightweight and fast, though currently best suited for smaller workloads. LanceDB also includes distributed indexing APIs for processing large datasets way more efficiently.
✅ Data Persistence and Reliability: Provides local data storage solutions and also distributed storage capabilities via the distributed indexing API.
✅ Integration Ecosystem: Integrates with various tools and frameworks, including Polars, Pydantic, and DuckDB, enhancing its versatility in handling diverse data workflows.
✅ Security and Compliance: LanceDB Cloud is SOC2 Type II and HIPAA certified, ensuring robust security and compliance for production use cases.
✅ Community and Support: LanceDB maintains an active developer community on Discord and Twitter. Also includes OS and enterprise cloud docs.
✅ Distribution and Licensing: Open-source (Apache 2.0), managed cloud (private beta; needs access request).
✅ Multi-modal Data Support: Designed to handle many different data types (text, images, videos, and point clouds) so it's easy to store and find multi-modal data.
Hosting & Cost
📌 Self-hosted: Free & open-source.
📌 Cloud Version: In private beta (request access).
Best For
Teams and developers building applications with multi-modal AI projects (images, video, text) that requireefficient storage and retrieval of diverse data types (e.g., search apps, recommendation systems).

🚀 Get Started Here: Quickstart with LanceDB.
🏁 Conclusion
The vector database landscape remains a cornerstone of modern AI applications, offering flexibility, scalability, and robust search capabilities to meet the growing demands of high-dimensional data processing. Each featured platform has unique strengths:
Milvus and Weaviate stand out for their scalability and suitability for large-scale AI and enterprise search.
ChromaDB excels in LLM fine-tuning and rapid prototyping, making it an ideal choice for experimental workflows.
Pinecone delivers cloud-managed scalability with high availability, tailored for production-ready environments.
Qdrant is optimized for low-latency vector search, making it a great choice for real-time applications.
LanceDB uniquely addresses multi-modal AI needs, integrating with frameworks like Hugging Face and OpenAI.
Choosing the right vector database depends on your specific use case, infrastructure requirements, and desired level of customization. As AI continues to evolve, vector databases will remain pivotal in enabling efficient and scalable handling of vector data.