
Fenic: DataFrames for an LLM world
Tool Review #12: Fenic turns LLM calls into first-class DataFrame ops (semantic.map, classify, extract, join). PySpark vibes, Arrow under the hood, Rust speed… but also a young ecosystem with sharp ed


Fenic just went public on GitHub (★ ~143, Apache 2.0, v0.2.1, July 7, 2025). The goal: treat LLM inference as a first-class DataFrame primitive, so everything from paraphrasing to schema extraction looks like a familiar df.select().

📢 What Is Fenic?
“Think pandas/Polars, but with
semantic.extract,semantic.join,semantic.mapbaked in.” — Kostas Pardalis, Fenic creator (MLOps Slack launch thread).
Under the hood, Fenic is an opinionated, PySpark-inspired query engine built from scratch for AI and agentic applications.
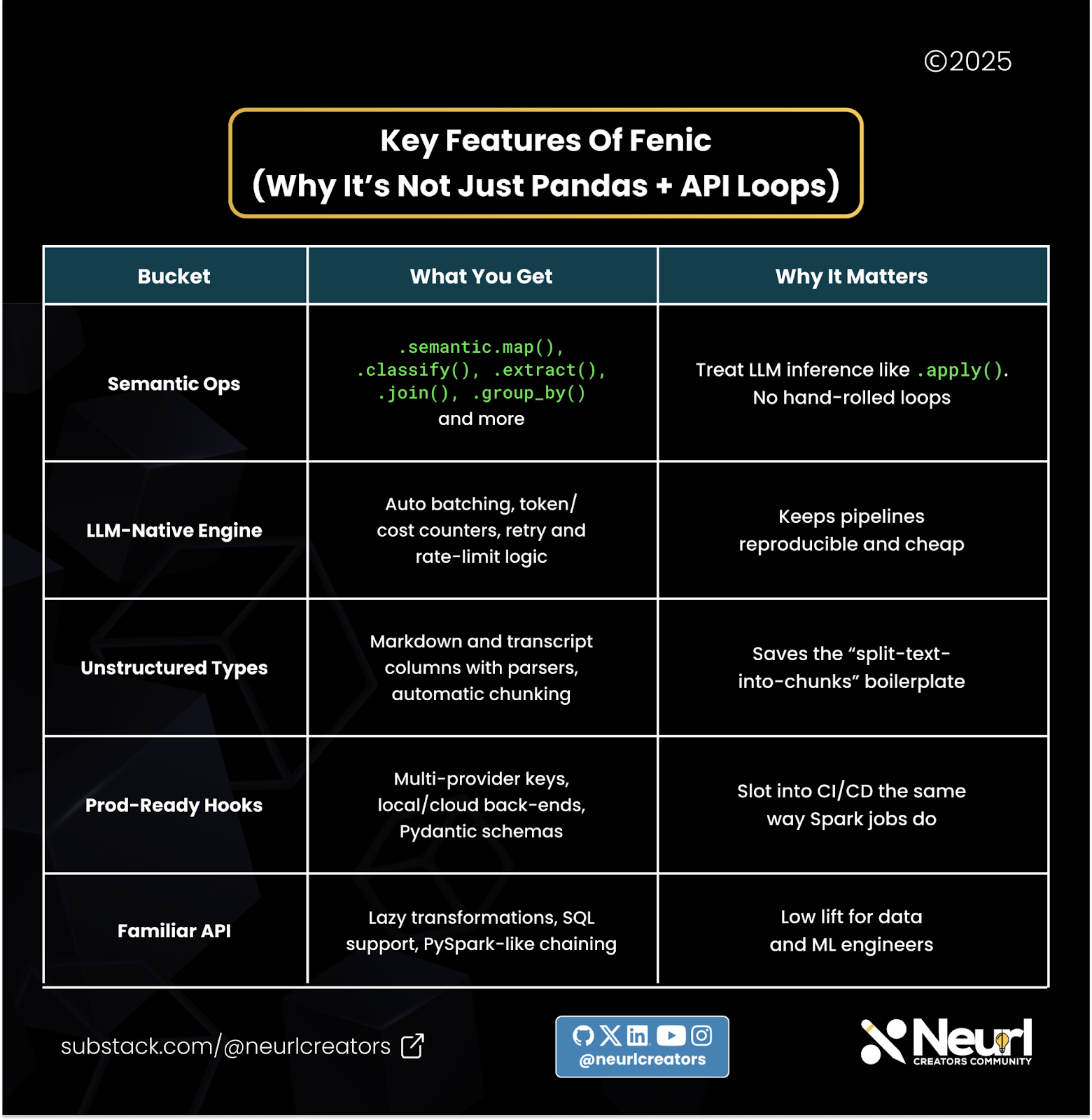
Fenic treats LLM workflows as built-in DataFrame primitives instead of attaching them to external systems. This approach might make it much easier to build and run your workflows.
Here are the primary selling points:
Semantic operators (
analyze_sentiment,classify,extract,group_by,join,predicate) are first-class.Native unstructured types: Markdown, transcripts, JSON, long-form text with auto-chunking.
Batch and retry layer with token counting and cost metrics built-in.
Multi-provider (OpenAI, Anthropic, Gemini) and local/cloud execution modes.
Familiar API: lazy DataFrame, SQL support, PySpark-like chaining.
Languages: Python 87%, Rust 13%. Rust core already powers Arrow-native execution, with design choices influenced by Polars for speed and efficiency.
Wes McKinney (pandas creator) publicly endorsed the concept (“a natural evolution of the DataFrame abstraction”).
⚡ Quick Spin-Up: Podcast → Segments → Extract → Summaries (Fenic)
Here’s a quick example of how to analyze and extract summaries from a podcast episode with Fenic:
pip install fenic # Python 3.10-3.12, Fenic v0.2.1
export OPENAI_API_KEY=... # Add your Op
# -------------------------
from pathlib import Path
from pydantic import BaseModel, Field
import fenic as fc
# 1. ---- Define schemas for structured extraction ----
class SegmentSchema(BaseModel):
speaker: str = Field(description="Who is talking in this segment")
start_time: float = Field(description="Start time (seconds)")
end_time: float = Field(description="End time (seconds)")
key_points: list[str] = Field(description="Bullet points for this segment")
class EpisodeSummary(BaseModel):
title: str
guests: list[str]
main_topics: list[str]
actionable_insights: list[str]
# 2. ---- Init a Fenic session with a model alias ----
config = fc.SessionConfig(
app_name="podcast_quickspin",
semantic=fc.SemanticConfig(
language_models={
"mini": fc.OpenAIModelConfig(model_name="gpt-4o-mini", rpm=300, tpm=150_000)
}
),
)
session = fc.Session.get_or_create(config)
# 3. ---- Load raw transcript/metadata as strings ----
data_dir = Path("data") # put your JSON/text here
transcript_text = (data_dir / "transcript.json").read_text()
meta_text = (data_dir / "meta.json").read_text()
df = fc.DataFrame({"meta": [meta_text], "transcript": [transcript_text]})
# 4. ---- Extract structured metadata & segment the transcript ----
processed = (
df.select(
"*",
fc.semantic.extract("meta", EpisodeSummary, model="mini").alias("episode"),
# Chunk transcript then extract per-chunk info
fc.semantic.chunk("transcript", max_tokens=1200).alias("chunks"),
)
# Explode chunks to rows (one row per chunk)
.explode("chunks")
.select(
fc.col("chunks").alias("chunk"),
fc.semantic.extract("chunk", SegmentSchema, model="mini").alias("segment"),
)
)
# 5. ---- Abstractive recap per speaker/segment & global summary ----
final = (
processed
.select("*",
fc.semantic.map(
"Summarize this segment in 2 sentences:\n{chunk}"
, model="mini").alias("segment_summary")
)
.group_by(fc.col("segment.speaker"))
.agg(
fc.semantic.map(
"Combine these summaries into one clear paragraph:\n{segment_summary}"
, model="mini").alias("speaker_summary")
)
)
final.show(truncate=120)
# Optional: write to parquet/csv
final.write.parquet("podcast_summaries.parquet")
session.stop()Tips to Adapt Quickly
Different providers: swap
OpenAIModelConfigforAnthropicModelConfig, etc.Bigger files: bump
max_tokensor chunk size; Fenic batches/streams for you.Eval pass: add another
select()with a classifier prompt to tag “quality: good/needs fix”.Cost guardrails: set
max_tokens_per_callor inspectsession.metrics()after run.
Need a variant for YouTube transcripts or research PDFs? Simply adjust the loader and schemas, and the pipeline shape will remain unchanged.
🔥 Why You Should Care
Declarative pipelines → push your ETL and inference into the same DAG.
Cheaper evaluation loops → token and cost metrics are first-class.
Semantic joins → fuzzy “does this paper help my research question?” join in one line via
semantic.joinStructured extraction to Pydantic → easier downstream analytics, eval & labeling.
Agent synergy → pre-batch heavy reasoning offline, feed lean contexts to online agents.
📉 Gotchas and Caveats
Toolchain friction: Installing Fenic via pip is straightforward, but developing new features requires the Rust toolchain (rustc, cargo, maturin), which isn’t fully documented yet.
Young ecosystem: Core support includes Arrow, CSV, and Parquet, with native connectors for Snowflake, BigQuery, and S3 expected soon.
Operational maturity: No proven large-scale benchmarks published; cloud engine still alpha.
Docs still sparse: docs.fenic.ai exists but is thin; many API details live only in README/examples. A more structured documentation system is in the works, with an MCP server example.
Single-node today: No distributed executor yet; large corpora need chunked runs or Spark/Polars fallback.

🧑⚖️ Final Verdict: 4/5
Rating: ⭐⭐⭐⭐☆ (4/5)
Fenic nails a gap nobody else covers: treating LLM inference as a native DataFrame primitive. If your team already loves SQL/PySpark and spends hours duct-taping looped API calls, Fenic will feel like a super-power.
Ship it if…
You batch-process lots of text and need semantic joins/extractions weekly.
You’re prototyping an RAG/agent pipeline and want repeatable, cost-aware ETL.
You can tolerate early-project rough edges and contribute fixes upstream.
Hold off if…
You need petabyte-scale, distributed compute today.
Your workloads are real-time, sub-second.
You require enterprise auth/row-level security out of the box.
📌 More Resources
Docs and Quickstarts → https://docs.fenic.ai/latest/
GitHub repo (Apache-2.0) → https://github.com/typedef-ai/fenic
Blog intro (“PySpark-inspired DataFrame for AI”) (June 18, 2025) → https://www.typedef.ai/blog/fenic-open-source
Example gallery → examples/ folder on GitHub
Author Q&A in MLOps Slack → link
Love this review? Forward it to your fellow data and MLOps friends, or share on X with #TuesdayToolReview and tag @mlopscommunity
Want deeper tutorials? Subscribe to The Neural Blueprint for hands-on guides! 🫡