


How NotebookLM Audio Overview Works
Explore the Inner Workings of Google's NotebookLM Audio Overview


TLDR
NotebookLM Audio Overview amazed audiences with its lifelike podcast-style dialogue synthesis.
Unlike traditional speech synthesis, which generates speech for a single speaker, dialogue synthesis creates realistic interactions between multiple speakers.
Two critical elements for producing natural-sounding speech are the semantic and acoustic representations of the dialogue.
NotebookLM employs a text-to-semantic model, similar to SpearTTS, to derive semantic representations from the conversation transcripts.
These semantic representations are then converted into acoustic representations, which are fed into advanced audio generation models like SoundStorm to produce realistic and engaging dialogues.

The world has experienced several groundbreaking "aha" moments in AI. The release of ChatGPT was one such milestone, showcasing just how advanced and capable AI has become. Another remarkable moment occurred recently with NotebookLM's Audio Overview. Its ability to generate podcast-style conversations virtually indistinguishable from human dialogue amazed many people.

Despite being a Google product, NotebookLM remained relatively obscure until its Audio Overview feature was introduced. Unlike ChatGPT, whose underlying architecture and model were well-publicized at launch, NotebookLM keeps its AI foundation a closely guarded secret, leaving everyone guessing about the technology powering it.
If you're curious about how NotebookLM's Audio Overview works, you've come to the right place. In this article, we'll break down the possible inner workings of NotebookLM.
You might be asking, how do we know this? Well, over the years, Google has released several models and research papers, especially in speech synthesis and dialogue synthesis, that closely align with how NotebookLM seems to operate.
By the end of this article, you will gain a clear understanding of the following:
The concepts of neural codecs, acoustic tokens, and semantic tokens, and their role in generating realistic audio.
The foundational models that power NotebookLM, such as Soundstream, AudioLM, SpearTTS, and SoundStorm.
How semantic and audio generation models work together to enable dialogue synthesis.
Foundations
At its core, NotebookLM’s Audio Overview is fundamentally a speech synthesis tool. However, it has been optimized to simulate dialogue between two speakers, making it more accurately described as a dialogue synthesis tool. Despite this optimization, the underlying mechanism remains rooted in speech synthesis.
To understand how NotebookLM works, we’ll first delve into a few foundational concepts essential for creating realistic speech synthesis. These concepts lay the groundwork for achieving seamless dialogue synthesis. Here are the three key topics we’ll explore:
Neural Codecs
Semantic Tokens
Acoustic Tokens
Neural Codecs
In audio processing, a codec converts analog signals into digital formats by compressing raw audio into a compact, computer-readable representation. This compression reduces file sizes while preserving essential audio quality, enabling efficient storage and transmission.
Neural codecs are advanced compression tools powered by neural networks, which allow them to learn and represent data more efficiently than traditional codecs.
While traditional codecs rely on predefined methods like Fourier transforms, discrete cosine transforms (DCT), and predictive coding to analyze and compress data, neural codecs leverage deep learning models to adaptively compress data into compact and meaningful vector representations.
An Autoencoder is a neural network architecture commonly used as a neural codec. It consists of two primary components:
Encoder: Compresses audio into a vector representation that captures its essential features.
Decoder: Reconstructs the audio from the vector representation, producing high-quality output.
Autoencoders, when applied as neural codecs, are well-suited for applications such as:
Streaming
Low-latency communication
Audio compression for storage and transmission

Autoencoders can be extended and improved to perform more advanced tasks, including:
Denoising with Denoising Autoencoders (DAEs):
DAEs are trained to remove unwanted noise from audio or other data types.
For example, a DAE can clean up background noise in an audio recording while preserving the original sound quality.
Speech Synthesis with Variational Autoencoders (VAEs):
VAEs introduce variability between input and output data by learning a probability distribution, known as the latent space.
In speech synthesis, VAEs can sample new vector representations from the latent space to generate entirely new speech audio.
This allows the creation of realistic speech, even for voices or sounds not explicitly included in the training data.
Vector Quantization
Quantization is a term common in audio processing. It involves converting continuous analog signals into discrete digital values by mapping them to a fixed set of levels.

Vector Quantization (VQ) extends this concept to neural networks. In a typical Variational Autoencoder (VAE), the latent space consists of continuous vector representations. However, when VQ is applied, these representations are transformed into discrete vectors, effectively converting the input data into a set of discrete vectors stored in a codebook. This modified version of the VAE is known as a VQ-VAE.

Thanks to its discrete vector representations, each entry in the codebook can capture distinct and meaningful features from the input data. For instance, in speech synthesis:
One vector might encode intonation.
Another vector could capture phoneme structure.
Some vectors might represent variations in tone.
Others could encode rhythm or prosody.
Residual Vector Quantization
Residual Vector Quantization (RVQ) is an advanced technique that builds upon the concept of Vector Quantization (VQ) to achieve more efficient and accurate data representation. While standard VQ maps input data into a single discrete vector from a codebook, RVQ introduces a multi-step process where the residual errors from each quantization step are iteratively refined.
In RVQ, the process works as follows:
Initial Quantization: The input data is first quantized into a discrete vector using the primary codebook, capturing the most significant features.
Residual Calculation: The difference (residual) between the original input and the reconstructed data from the first quantization is calculated.
Refined Quantization: The residual error is then quantized using a secondary codebook, designed to encode finer details not captured in the initial step.
Iterative Refinement: This process can be repeated multiple times with additional codebooks, progressively improving the representation by encoding smaller and smaller residuals.
RVQ is particularly useful in scenarios where high fidelity is required, such as speech synthesis, audio compression, and even video encoding. For example, in speech synthesis:
The first quantization step might encode broad intonation patterns.
Subsequent steps refine phoneme structure, tone variations, and micro-prosodic details.
By combining multiple levels of quantization, RVQ achieves a highly detailed and compact representation while minimizing reconstruction errors. This makes it an invaluable tool for tasks that demand efficient and high-quality data processing.
Acoustic and Semantic Representation
The vector representation of a neural codec can encode various types of information. In the context of speech synthesis, these representations can be broadly categorized into two types:
Acoustic Representation
Semantic Representation
Acoustic Representation
Acoustic representation captures the detailed audio characteristics present in speech. These features include:
Pitch: The perceived frequency of the voice, which contributes to tone and melody.
Intensity: The loudness or energy level of the speech.
Duration: The length of speech segments, such as phonemes or words.
Prosody: The rhythm, stress, and intonation patterns in speech.
Speaker Identity: Features that distinguish individual speakers, such as vocal timbre.
Recording Conditions: Environmental factors like background noise or microphone quality.
By leveraging these acoustic details, neural codecs can create more realistic and expressive speech synthesis outputs.
Semantic Representation
While acoustic representation captures the audio characteristics of speech, it does not encompass linguistic information. Without semantic representation, speech is akin to a baby babbling or someone uttering gibberish, lacking meaningful structure or coherence.
Semantic representation encodes the linguistic and structural aspects of language, enabling speech synthesis systems to generate intelligible and contextually appropriate content. Key elements captured in semantic representation include:
Word Meaning: The specific definitions and connotations of individual words.
Contextual Meaning: How word meanings shift based on surrounding text or discourse.
Intent or Purpose: The underlying goal or message conveyed by the speech.
Polysemy: The ability to differentiate between multiple meanings of a word based on context.
Logical Relations: The connections and relationships between ideas, such as cause-effect or contrast.
By integrating semantic representation, speech synthesis can produce output that is not only acoustically realistic but also linguistically meaningful and contextually relevant.
Foundational Models That NotebookLM Builds Upon
Having examined the foundational concepts essential for generating high-quality speech synthesis, we can now explore the primary models that served as groundwork for the development of NotebookLM. These pioneering efforts laid the foundation for its advanced capabilities:
SoundStream: A sophisticated neural audio codec that introduced efficient methods for compressing and reconstructing audio with high fidelity.
AudioLM: An innovative audio generation model that applies language modeling concepts to produce coherent and contextually accurate audio sequences.
SpearTTS: A groundbreaking Text-to-Speech model that mimics the human process of reading and speaking, delivering natural and expressive audio.
SoundStorm: A highly efficient audio generation model that leverages non-autoregressive techniques to produce seamless and high-quality audio.
SoundStream
SoundStream is a neural codec introduced by Google in the paper SoundStream: An End-to-End Neural Audio Codec. It is designed to efficiently compress audio and reconstruct it with high quality, outperforming traditional codecs like Opus and EVS in compression performance.
How Does it Work?
SoundStream employs an encoder-decoder architecture:
Encoder: Transforms the input audio into a compressed latent representation.
Residual Vector Quantization (RVQ): Used within the architecture to achieve highly efficient compression by breaking down the latent representation into multiple discrete components for better reconstruction.
Decoder: Reconstructs the high-quality audio from the compressed latent representation.

Additionally, SoundStream incorporates a discriminator network during training. The discriminator compares the original input audio with the reconstructed output audio, ensuring that the reconstructed audio is nearly indistinguishable from the original. The codec is trained adversarially so that the discriminator cannot differentiate between the two, leading to improved reconstruction quality.
AudioLM
AudioLM is a model introduced by Google in the paper AudioLM: A Language Modeling Approach to Audio Generation. It falls under a category of models known as Textless NLP, as it adapts language modeling concepts to audio, replacing text with sound.
AudioLM repurposes traditional language modeling tasks for audio. In a conventional language model, the model is trained to predict and complete text. In contrast, AudioLM is trained to complete audio: given a portion of audio, the model predicts what comes next while maintaining both the acoustic and semantic features of the input.
How Does It Work?
AudioLM consists of two primary components:
SoundStream: Provides AudioLM with the necessary acoustic representation. The encoder of SoundStream utilizes Residual Vector Quantization (RVQ) to efficiently compress and represent audio, producing the acoustic representation that AudioLM depends on.
w2v-BERT: A BERT-inspired model adapted for audio, which supplies AudioLM with the semantic representation of the input audio.

These representations are processed hierarchically. First, the semantic representation from w2v-BERT is used to guide the generation of the acoustic representation. The RVQ-based acoustic representation from SoundStream’s encoder is then passed through the SoundStream Decoder.

The process starts with an initial audio prompt, and through the combination of these models, AudioLM generates a continuation of the audio, maintaining consistency in both its acoustic properties and semantic meaning.
SpearTTS
SpearTTS is a speech synthesis model introduced by Google in the paper Speak, Read, and Prompt: High-Fidelity Text-to-Speech with Minimal Supervision. It takes an innovative approach to generating speech by framing the problem as a translation task, where text is transformed from its written form into audio. This method leverages techniques similar to those used in the original Transformer model.
How Does It Work?
SpearTTS models the way humans process and produce speech. When given a piece of text, the first step is understanding its meaning, followed by vocalizing it with appropriate adjustments in tone and intonation.
SpearTTS follows a similar process:
Text Input: The model starts with text, which is first converted into a semantic representation.
Semantic Representation: The semantic information is then transformed into an acoustic representation, capturing the speech features.
SoundStream Decoder: This acoustic representation is fed into the SoundStream decoder, which converts it into high-quality speech.
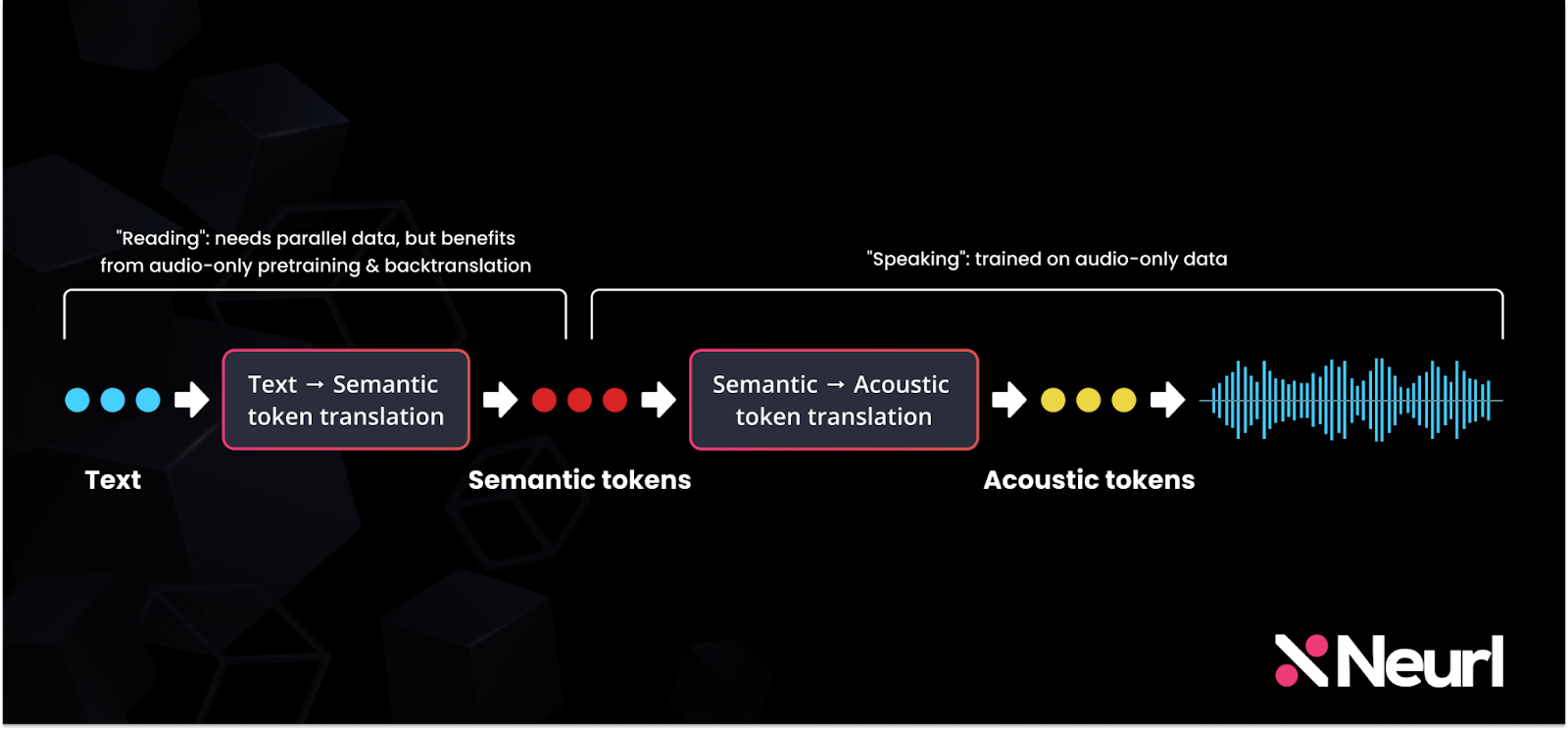
What distinguishes SoundStream in SpearTTS from AudioLM is that, instead of being conditioned on audio segments, it is conditioned on text. This enables SpearTTS to directly translate text into its audio equivalent while maintaining both acoustic and semantic details throughout the process.
SoundStorm
If there's any paper that unveils the inner workings of NotebookLM, it's SoundStorm: Efficient Parallel Audio Generation, another paper by Google. This paper introduces SoundStorm, an audio generation model that enhances the efficiency of the audio generation process by employing non-autoregressive strategies. As a result, SoundStorm produces high-quality audio even for longer sequences.
How Does It Work?
SoundStorm leverages the semantic representation provided by AudioLM and generates audio by filling in masked regions of the output iteratively. This process continues until the entire audio sequence is completed, ensuring high-quality and coherent results throughout.
The SoundStorm audio generation model can also replace the audio generation component of AudioLM. Like AudioLM, SoundStorm can be prompted with audio segments as well, making it a flexible and powerful tool for both audio generation and completion tasks.
Creating NotebookLM: Integrating Semantic and Audio Generation Models
The moment we've all been waiting for is here, how does NotebookLM work? At its core, NotebookLM likely combines the powerful models we've explored in previous sections, integrating their capabilities into a cohesive system for dialogue synthesis.
From Speech Synthesis to Dialogue Synthesis
Previously, we discussed the efficient speech generation capabilities of SoundStorm, which utilizes semantic representations from AudioLM. But SoundStorm doesn’t stop at generating a single speaker's voice, it can also handle dialogue synthesis, where two speakers engage in a back-and-forth conversation.
This is a significant leap beyond single-speaker speech synthesis. Dialogue synthesis requires the model to manage two distinct speaker identities while ensuring smooth transitions between turns, making the conversation feel natural and cohesive.
Training Process for Dialogue Synthesis
To achieve this, the SoundStorm model was trained using a specialized dataset containing conversations between two speakers and their corresponding transcriptions. Here’s how the process works:
Dataset Preparation:
Conversations were annotated to distinguish between speakers, ensuring that the model could learn to identify and maintain speaker identities.
Segments of the audio were removed during training, keeping only the initial portion of the audio while retaining the full transcript.
Semantic Representation:
The remaining transcript was passed to a text-to-semantic model, similar to the one used in SpearTTS.
This model converted the transcript into a semantic representation, which captures the meaning and context of the text.
Acoustic Representation:
The semantic representation was then transformed into an acoustic representation, which preserves the nuances of each speaker's voice.
Audio Completion:
SoundStorm used the acoustic representation to generate the missing audio, ensuring that transitions between speakers were smooth and natural.
Unlike SpearTTS, which handles single-speaker synthesis, the dialogue synthesis process required SoundStorm to manage two speaker identities simultaneously. The model’s ability to generate both voices together allowed for seamless transitions, closely mimicking natural conversations.
Generating Dialogue Audio: The Inference Workflow
During inference, the SoundStorm dialogue model is tasked with completing a conversation's audio based on a provided transcript. While the full transcript is available, only the initial portion of the audio is supplied. The model’s goal is to generate the remaining audio, ensuring it aligns with the transcript while maintaining the semantic and acoustic characteristics of each speaker.
Here’s how the process works:
Input Prompt:
A short snippet of the audio, containing the first two dialogue turns, is provided as the input:
Audio:
The full transcript of the dialogue, covering all speaker turns, is available:
Transcript:
Speaker 1: Where did you go last summer?
Speaker 2: I went to Greece, it was amazing.
Speaker 1: Oh, that's great. I've always wanted to go to Greece. What was your favorite part?
Speaker 2: Uh it's hard to choose just one favorite part, but yeah I really loved the food. The seafood was especially delicious.
Speaker 1: Yeah.
Speaker 2: And the beaches were incredible.
Speaker 1: Uhhuh.
Speaker 2: We spent a lot of time swimming, uh sunbathing, and and exploring the islands.
Speaker 1: Oh that sounds like a perfect vacation! I'm so jealous.
Speaker 2: It was definitely a trip I'll never forget.
Speaker 1: I really hope I'll get to visit someday!
Semantic Conversion:
The model converts the remaining transcript into semantic tokens, capturing the context, tone, and meaning of the conversation.
Acoustic Conversion:
Using the semantic representation, the model generates an acoustic representation, preserving each speaker's unique voice characteristics.
Audio Completion:
SoundStorm utilizes the acoustic representation to synthesize the remaining dialogue, seamlessly integrating it with the initial audio.
Example output audio:
By leveraging its advanced text-to-semantic-to-audio pipeline, SoundStorm ensures that the completed audio is natural, coherent, and faithful to both the transcript and the voices of the speakers. This process allows for high-quality dialogue synthesis.
How This Differs from the Actual NotebookLM
While there are many similarities between the approach proposed in the SoundStorm paper and the methods likely used in NotebookLM, there are key differences that set them apart:
Initial Prompt:
Unlike SoundStorm, NotebookLM does not rely on an initial prompt audio. This indicates that NotebookLM can work directly with transcripts, converting them into audio without needing a starting audio segment.Consistent Speaker Identities:
NotebookLM maintains the same speaker identities across all conversations In contrast, the SoundStorm paper models speaker identities from the initial audio prompt.Duration of Dialogues:
The method described in the SoundStorm paper is limited to generating dialogues of up to 30 seconds. NotebookLM's underlying model seems to have undergone significant advancements, likely extending the duration and complexity of generated dialogues.
These distinctions highlight how the approach outlined in the SoundStorm paper was refined and enhanced to provide a significantly improved user experience in NotebookLM.
How NotebookLM truly works?
Having explored the approach presented in the SoundStorm paper and how it differs from the NotebookLM methodology, let’s infer how NotebookLM’s audio generation process works in practice.
User Uploads Document: The user begins by uploading a document to the NotebookLM platform.
Document Processing by Gemini: Once the document is uploaded, the Gemini model takes over. It generates a back-and-forth conversation transcript between two speakers, ensuring that each speaker is properly annotated.
Prompting Gemini: To generate these dialogues, Gemini is likely prompted with instructions like, “Given the document, create a deep-dive conversation in podcast style between two speakers—one acting as a host and the other as a guest speaker.”
Dialogue Synthesis: The generated dialogue transcript is then passed to a dialogue synthesis model, which performs the task of converting the text into speech while ensuring that both speakers are represented consistently throughout the conversation.
We can't be completely certain that this is exactly how NotebookLM's audio generation works, but based on the insights from the paper and our everyday experience with the platform, we're not too far off.
Conclusion
One of the most remarkable aspects of NotebookLM’s audio overview is how convincingly human it sounds. The first time you listen, it’s almost impossible to guess that it’s AI-generated. Who would have thought the Turing test could take the shape of a podcast?
When groundbreaking AI products like NotebookLM emerge, it’s easy to feel like the innovation happened overnight. But as we’ve explored through these research papers, the reality is much deeper. These technologies are the result of years of relentless research, countless iterations, and breakthroughs that build upon one another. The final step is when a visionary product team transforms these innovations into something tangible, an experience like NotebookLM that feels magical yet is rooted in scientific dedication.
FAQs
What is Dialogue Synthesis, and why is it important?
Dialogue synthesis is the process of generating natural, coherent conversations between two or more speakers using AI models. Models like SoundStorm recreate back-and-forth conversations while maintaining speaker identities and conversational flow.
What are acoustic details in speech, and why do they matter?
Acoustic details refer to the characteristics of sound waves in speech, such as pitch, tone, rhythm, and timbre. These, along with recording conditions, such as background noise, microphone quality, and room acoustics, are all part of the acoustic details that ensure the generated audio is realistic and expressive.
What are semantic details in speech, and how are they used?
Semantic details in speech represent the meaning or intent behind spoken words, captured as abstract representations or tokens. These details are used by AI models to ensure that the generated audio aligns contextually with the intended message.
What is vector representation, and what information does it capture in speech models?
Vector representation is a numerical encoding of data, such as audio or text, into a multidimensional space. In speech models, vectors capture various features, including semantic meaning, acoustic properties, and contextual relationships. These representations enable AI systems to process and generate speech efficiently while preserving the essence of the original input, such as speaker identity and conversational context.
What makes SoundStorm unique among audio generation models?
SoundStorm stands out due to its non-autoregressive approach, enabling it to generate high-quality audio much faster than traditional methods. By iteratively filling in missing audio segments using semantic and acoustic representations, it achieves remarkable efficiency while maintaining natural sound quality.
What are VQ and RVQ in Audio Generation?
VQ (Vector Quantization) is a technique for compressing data by mapping it to a finite set of codebook vectors. It reduces the complexity of audio data while preserving essential features.
RVQ (Residual Vector Quantization) is an extension of VQ that uses multiple stages of quantization. Each stage quantizes the residual (difference) left after the previous stage, enabling more precise audio representation. Together, VQ and RVQ are essential for efficient audio compression and reconstruction, maintaining high fidelity in generated speech.