
[VIDEO] See the 5 Vector Databases for Your AI Agents in 2025
BuildAIers Toolkit #8: Discover which vector database powers your RAG, semantic search, and multimodal AI applications best in 2025—plus key updates & performance insights.


This review originally appeared in the MLOps Community Newsletter as part of our weekly column contributions for the community (published every Tuesday and Thursday).
Want more deep dives into MLOps tools and trends? Subscribe to the MLOps Community Newsletter (20,000+ builders)—delivered straight to your inbox every Tuesday and Thursday! 🚀
Every ambitious AI builder hits the same wall: storing and searching high‑dimensional data at human‑speed scale.
In 2023, we hacked around it with JSON, keyword indexes, and a prayer. By 2025, those shortcuts cost real money—lost users, ballooning GPU bills, and 3 a.m. on‑call pings.
That’s why vector databases have continued to be core infrastructure in 2025 for most AI teams we have spoken to. They’re the engines under today’s retrieval‑augmented generation (RAG) systems, multimodal search, and agentic workflows. But the market is crowded, the benchmarks are noisy, and “open‑source” doesn’t always mean “free.”
In this week’s Tuesday Tool Review, we pit the five platforms developers mention most—Milvus, Pinecone, Weaviate, Qdrant, and ChromaDB—against the real‑world metrics that matter:
tail‑latency under load
hybrid‑search versatility
zero‑ops convenience
and total cost to maintain.
If you’re building the next viral AI agent, shipping a multi‑tenant RAG API, or simply tired of wrestling full‑text indexes that were never designed for vectors, this quick, visual guide will help you pick a store that won’t crumble when your startup hits Product Hunt’s front page.
Grab a coffee and a fresh notebook. By the end, you’ll know exactly where to stash your embeddings so your models—and your users—never miss a beat.
Here’s what you’ll learn:
Why the surge in agentic workloads makes vector‑store performance your new SLA bottleneck
How each platform’s latest 2025 release reshapes the trade‑off between cost, speed, and operational freedom
A decision matrix to help you match your use case—whether prototyping on a laptop or serving multimodal search in production—to the right engine
⚡ TL;DR (bookmark this)
Want a deeper dive? We published a more in-depth guide on the “Top 6 AI Vector Databases Compared (2025): Which One Should You Choose as an AI Builder?”
📢 Why Vector DBs Still Matter in 2025
So you might be thinking, “Vector DBs? LMAO. So 2024!”, but not quite. Let’s see why:
RAG is still a production safety net: Most LLM apps still pair a model with a vector store to cut hallucinations.
More multimodal surge: As you probably know, the embeddings for images, audio, and video need very different index tricks vs. plain text. Even with OpenAI releasing the gpt-image-1 API in April, your use case might still require building a workflow around the API to use your embeddings.
Latency = UX: Sub‑second similarity search is the difference between a snappy AI assistant and a loading spinner.
Cost discipline: Serverless pricing and clever compression (PQ, scalar quantization) mean you can ship without a seven‑figure bill.
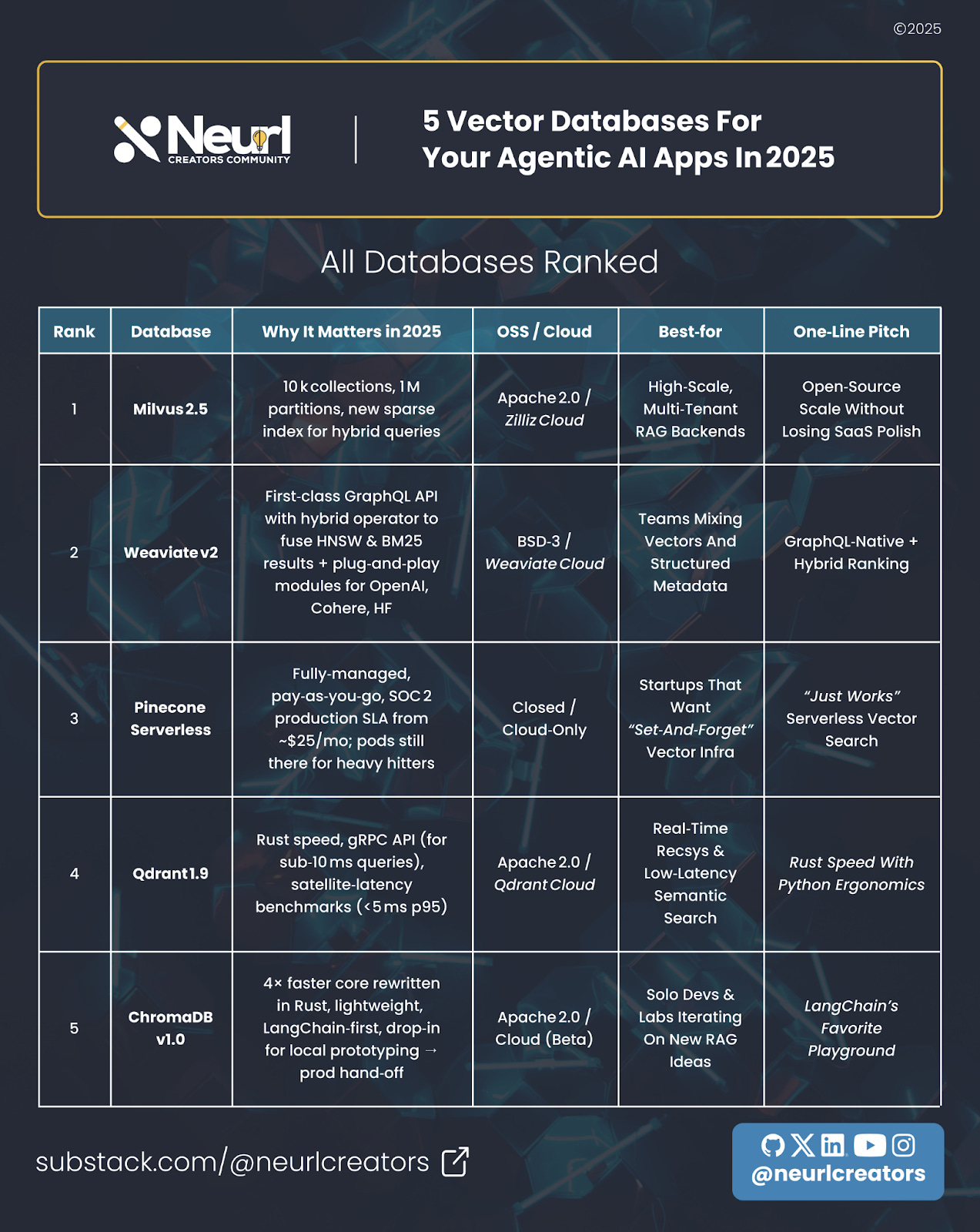
1️⃣ Milvus 2.5 – Scale Monster with New Tricks
What’s new? Partition‑Key isolation and a DAAT MaxScore sparse index mean you can cram 10k collections & 1 M partitions into a single cluster without crying over latency. Self‑host for free or let Zilliz Cloud babysit it.
Why devs love it
Horizontal shards that actually heal themselves.
SDKs in Python, Go, Node, Java—plug straight into LangChain or LlamaIndex with connectors.
Pricing that starts at “Git clone.” Perfect when the CFO side‑eyes your infra bill.
Watch‑outs
Overkill for hobby projects; cluster tuning takes time.
Best for: Multi‑tenant SaaS, recommendation engines, anything with billions of vectors and a board deck that says “scale.”
Use Milvus if… you need open‑source flexibility today and a SaaS upgrade path tomorrow.
👉 Quickstart: Documentation | cloud.zilliz.com
2️⃣ Weaviate v2 – GraphQL‑First Hybrid Search
One query, two brains. Weaviate’s hybrid operator merges vector similarity (HNSW) with BM25 keyword scoring, tunable by weights.
Why devs love it
GraphQL endpoint feels native to full‑stack devs.
Bring your own embeddings (OpenAI, Hugging Face) or let the built‑in Transformers module do the heavy lift.
SOC2 & RBAC tick enterprise‑security checkboxes.
Watch‑outs
GraphQL learning curve; JVM memory footprint can spike on huge corpora.
Best for: Apps with rich schemas (product catalogs, knowledge graphs) where keyword and vector relevance matter.
Use Weaviate if… you love GraphQL or need keyword+vector in one endpoint.
👉 Quickstart: Documentation | console.weaviate.cloud
Need creative, high-quality technical content? Happy to chat! Book a call with our Creative Engineers👇🏾
3️⃣ Pinecone – Serverless Convenience, Enterprise SLA
What’s new? Pinecone’s serverless indexes went GA with per‑request pricing (~$25/mo base) and $100 free credit for side projects.
Why devs love it
Scale: serverless auto‑shards; single‑region latency ≈ 50‑100 ms p95. So zero‑ops scaling—index growth, backups, SOC‑compliance, region moves are handled for you.
Language‑agnostic SDKs (Python → Rust) and first‑party LangChain wrappers.
Three distance metrics (cosine, dot, Euclidean) cover 99 % of RAG recipes.
Watch‑outs
Vendor lock‑in; no on‑prem story.
Best for: Prod workloads that need minutes‑to‑launch time‑to‑value and can live with closed source. Also for when MLOps folks say “that’s not my budget line” and you still need five 9s.
Use Pinecone if… you want “drop‑in” vector search without worrying about clusters or replicas.
👉 Quickstart: docs.pinecone.io
4️⃣ Qdrant – The Rust Rocket
Rust‑powered latency plus gRPC and REST APIs. Performance‑wise, its HNSW core plus gRPC API keeps p‑99 latency in single‑digit milliseconds and 50 % lower p50 latency than pgvector at 90 % recall.
Why devs love it
Scalar & product quantization options trim RAM on giant corpuses.
Snapshots + WAL persistence = zero‑data‑loss assurance—durability without vendor lock‑in.
Can run bare‑metal, in Kubernetes, or on Qdrant Cloud starting at 💰0 for a 1 GB playground.
Watch‑outs
Distributed mode requires careful shard planning; RBAC is enterprise‑only today.
Best for: Real‑time personalization or semantic search apps where every millisecond counts (p99 latency < 100 ms is non‑negotiable), and you want OSS + slick managed fallback.
Use Qdrant if… latency is king and you want open‑source + managed escape hatch.
👉 Quickstart: qdrant.tech | cloud.qdrant.io
5️⃣ Chroma v1.0 – From Notebook to Prod Fast
The LangChain playground. A single‑binary install (even pip install chromadb) that lets you hack local RAG chains fast. Local Chroma is 4× faster on writes & queries with the Rust rewrite in v1.0 pre‑release. A managed cloud is rolling out (wait‑list), so migrating prototypes won’t hurt.
Why devs love it
Tiny footprint: run chroma run on your laptop, ship to the cloud later.
LangChain, DSPy, and LlamaIndex integration out of the box.
Works great for multi‑modal embeddings if you’re tinkering with images or audio.
Watch‑outs
Single‑node by default; limited auth / multi‑tenant controls until the managed service leaves waitlist.
Best for: Gov‑cloud‑phobic teams, local notebooks, or edge deployments where you own the metal.
Use Chroma if… you’re iterating LLM apps on your laptop or bundling an embedded DB into edge devices.
👉 Quickstart: docs.trychroma.com
⚖️ Decision Matrix

🧰 Quick Wins for BuildAIers This Week
Kick the tires: Load the same 1 M‑vector dataset into Pinecone Free Tier and Milvus Lite; compare latency and dev‑ex overhead.
Hybrid test: Point Weaviate at your Elasticsearch index and add HNSW vectors—measure recall vs. classic BM25.
Latency drill‑down: Use the Qdrant points/index API with scalar quantization turned on and see the memory savings (~4‑8×).
Please drop your findings (good and ugly) in the comments.
🧑🚀 Final Verdict
Vector stores aren’t “nice‑to‑have” anymore—they’re core to every serious AI app. The good news? Some good options out there. The bad news? You still need to test with your embeddings, your query patterns, and your wallet.
Rating the field:
⭐ Ease of Use – Pinecone, ChromaDB
⚡ Raw Performance – Qdrant, Milvus
🔗 Integration Flexibility – Weaviate, Milvus
💰 Cost Control – Milvus OSS, Pinecone Serverless free tier
Pro tip: Whichever DB you choose, measure P95 latency under realistic concurrent load—not just single‑query benchmarks.
Start building today! Want the full step-by-step tutorial? We published a more in-depth guide on the “Top 6 AI Vector Databases Compared (2025): Which One Should You Choose as an AI Builder?” in The Neural Blueprint.
Check out our full video below and subscribe 🔔
Enjoy this? Please forward it to an AI builder friend or share it on X with #NeuralBlueprint and tag us @neurlcreators 🫡